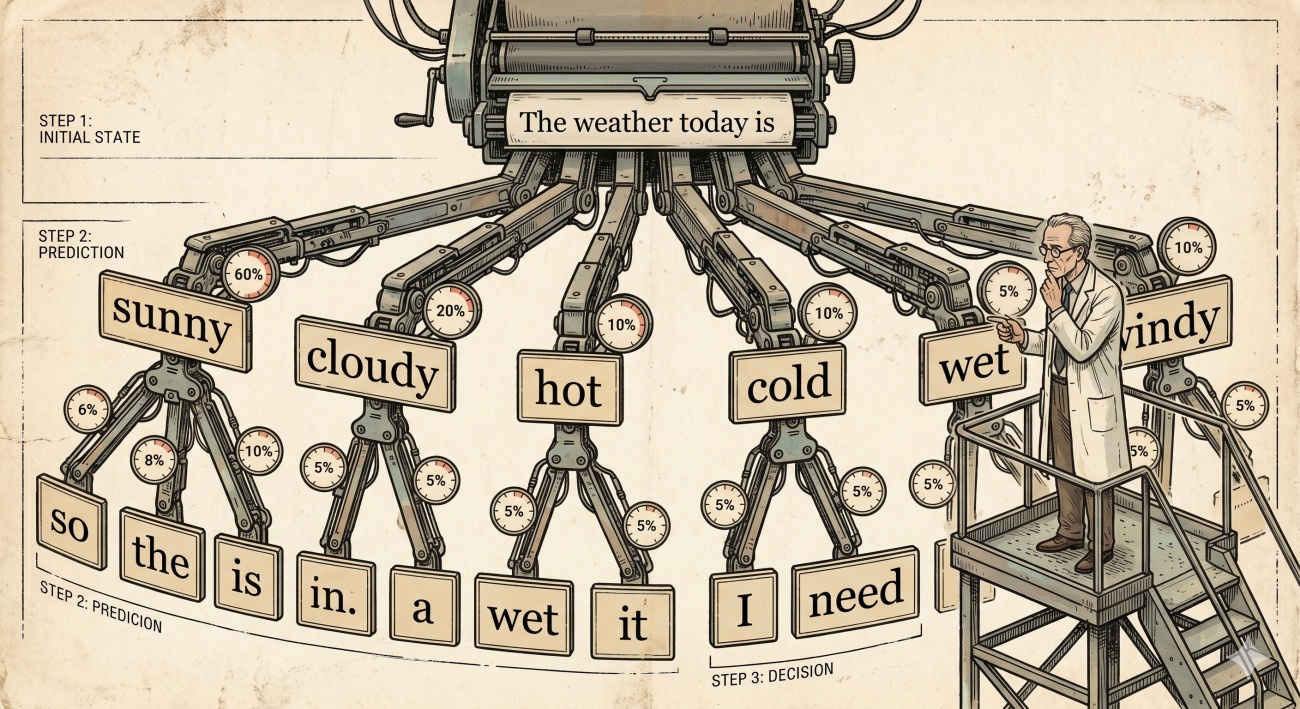
다음 토큰 예측이 왜 ‘이해처럼 보이는 능력’을 만드는가.
2회차에서 우리는 상징주의 AI가 남긴 발걸음들을 확인했다. 기호는 세계에 접지되어야 한다. 규칙을 따르는 것과 이해하는 것은 다르다. 그런데 AI 연구는 이 걸음에 응하는 대신, 다른 길을 택했다. 규칙을 설계하는 것을 포기하고, 데이터에서 패턴을 학습하는 방향으로 무게중심을 옮긴 것이다. 그 결과가 오늘날의 LLM이다. 그런데 LLM이 실제로 어떻게 작동하는지를 들여다보면, 처음에는 약간 허탈한 느낌이 든다. 이토록 인상적인 결과물이 이렇게 단순한 원리에서 나온다고? 싶을 만큼.
LLM의 핵심 작동 원리는 한 문장으로 요약할 수 있다. 주어진 텍스트 다음에 올 가능성이 가장 높은 토큰을 예측한다. 여기에서 토큰은 대략 단어나 단어의 일부라고 생각하면 된다. ‘오늘 날씨가’라는 텍스트가 주어지면, 그 다음에 올 가능성이 높은 토큰으로 ‘좋다’, ‘흐리다’, ‘덥다’ 등을 예측하는 것이다. 이 예측을 반복하면서 문장이, 그리고 문단이, 나아가 글이 만들어진다. 물론 실제 작동은 훨씬 복잡하다. 수천억 개의 파라미터, 방대한 학습 데이터, 정교한 어텐션 메커니즘. 하지만 근본적인 원리는 이것이다. ‘다음에 올 가능성이 높은 것을 예측한다.’ 그럼 이제 자연스러운 질문이 생긴다. 그게 다야? 그걸로 어떻게 저렇게 복잡한 질문에 답하고, 코드를 짜고, 글을 분석하는 거지?
이 질문에 답하려면 LLM이 학습한 데이터의 규모를 먼저 생각해야 한다. 인터넷에 존재하는 방대한 텍스트, 책, 논문, 대화, 코드. 인류가 언어로 기록한 거의 모든 것이 학습 데이터에 포함되어 있다고 해도 과언이 아니다. 그리고 이 데이터 속에는 엄청난 패턴이 숨어 있다. 어떤 개념이 어떤 맥락에서 등장하는가. 어떤 질문 다음에 어떤 종류의 답이 오는가. 어떤 논증 구조가 설득력 있다고 여겨지는가. 어떤 감정적 맥락에서 어떤 표현이 쓰이는가. LLM은 이 모든 패턴을 통계적으로 내면화한다. 그 결과, ‘다음 토큰 예측’이라는 단순한 작업은 놀라운 부산물을 만들어낸다. 논리적으로 일관된 추론처럼 보이는 텍스트, 맥락을 파악한 것처럼 보이는 응답, 창의적인 것처럼 보이는 연결. 이것들이 실제로 이해에서 비롯된 것인지, 아니면 이해처럼 보이는 패턴의 정교한 재현인지, 그것이 지금 논쟁의 핵심이다.
한 가지 예를 들어보자. LLM에게 “이 시의 주제는 무엇인가”라고 물으면 그럴듯한 분석이 돌아온다. 이미지, 리듬, 화자의 감정, 역사적 맥락까지. 그런데 이 분석이 나오는 과정에서 LLM은 시를 ‘읽고’ 느끼는 게 아니다. 이런 시 다음에 이런 분석이 오더라는 패턴을 학습했고, 그 패턴에 따라 텍스트를 생성한 것이다. 분명, 그 과정을 인간이 시를 읽는 경험과 같은 의미의 이해라고 부르기는 어렵다. 하지만 문제는 여기에서 끝나지 않는다. 그 결과가 우리가 이해의 산물이라고 불러온 것과 너무 닮아있을 때, 우리는 다시 질문하게 된다.
이 부분에서 많은 사람들이 두 가지 방향으로 혼동을 일으킨다. 한쪽은 이렇게 말한다. “결국 통계적 패턴 매칭 아냐? 이해라고 부를 수 없지.” 이 입장은 상징주의의 직관을 물려받았다. 진짜 이해에는 내부의 의미 표상이 있어야 하고, 명시적인 추론 과정이 있어야 한다. LLM에는 그게 없으니 이해가 아니다. 다른 쪽은 이렇게 말한다. “결과가 저 정도면 이해하는 거잖아. 왜 자꾸 내부를 문제삼는거야?” 이 입장은 행동주의의 직관에 가깝다. 이해를 판단하는 건 내부 구조가 아니라 외부 행동이다. 그리고 LLM의 행동은 이해의 증거로 충분해 보인다. 이 두 입장이 평행선을 달리는 이유는, 사실 서로 다른 질문을 하고 있기 때문이다. 전자는 “어떻게 작동하는가”를 묻고, 후자는 “무엇을 할 수 있는가”를 묻는다. 그리고 이 두 질문은, 반드시 같은 답을 가리키지 않는다.
그리고, 한 가지 더 복잡한 문제가 생긴다. LLM이 추론처럼 보이는 텍스트를 생성할 때, 그것이 ‘추론을 한다’는 건지 ‘추론처럼 보이게 말한다’는 건지, 외부에서는 판별하기가 매우 어렵다. 심지어 연구자들도 이 경계, LLM의 추론 능력을 놓고 지금도 논쟁 중이다. 결국 LLM 내부는 본질적으로 블랙박스에 가깝고, 어떤 과정을 거쳐 특정 응답이 나왔는지 완전히 추적하는 것은 현재 기술로는 불가능하다.
(해당 논쟁에 대해 두 가지 논문을 예로 들 수 있다. 대표적으로 Bubeck et al. (2023)의 “Sparks of Artificial General Intelligence” (Microsoft Research)는 GPT-4의 추론 능력에 주목했고, 반론으로 Bender et al.(2021)의 “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” 등이 LLM 추론의 한계를 지적한다. (관련 논의 개요: https://arxiv.org/abs/2303.12712)
LLM은 세계를 직접 겪지 않는다. 하지만 세계에 대해 사람들이 남긴 말들을 엄청난 규모로 학습한다. 그러므로 LLM의 언어는 세계와 완전히 무관하지 않지만, 그렇다고 세계에 직접 닿아 있지도 않다. 이 애매한 중간지대가 우리를 혼란스럽게 만드는 것이다. 이 지점에서 한 가지 중요한 사실을 짚어야 한다. LLM이 만들어내는 ‘그럴듯함’이 단순히 표면적 모방이 아닐 수 있다는 것이다. 언어는 세계와 무관하게 존재하지 않는다. 텍스트 속에는 세계에 대한 정보가, 사람들의 경험이, 개념들 사이의 관계가 이미 녹아 있다. 언어를 충분히 학습한다는 것은, 어떤 의미에서는 그 언어가 담고 있는 세계의 구조를 간접적으로 내면화하는 것이기도 하다. 계산언어학 분야의 연구들은 오래전부터 이 가능성을 탐색해왔다. 텍스트의 분포 패턴만으로도 개념 간의 의미적 관계를 상당히 정확하게 포착할 수 있다는 연구들이 축적되어 있다. 단어는 그것이 함께 등장하는 다른 단어들로부터 의미를 얻는다는 분포 의미론(Distributional Semantics)의 직관이 LLM의 인상적인 성능을 부분적으로 설명한다.
(분포 의미론의 기초적 논의로는 Turney, P. D., & Pantel, P. (2010). “From Frequency to Meaning: Vector Space Models of Semantics.” Journal of Artificial Intelligence Research, 37, 141–188. 를 참고해 볼 수 있다. 공개본은 https://arxiv.org/abs/1003.1141)
하지만 동시에 한계도 있다. 텍스트에서 학습한 패턴은 세계를 간접적으로 반영하지만, 그것이 직접적인 경험이나 검증과 같지는 않다. “비가 온다”는 텍스트 패턴을 수십억 번 학습한 것이, 비를 맞아본 경험과 같은 의미의 접지를 제공하는가. 이것은 당연히, 그리고 여전히 열린 질문이다.
다시 현장으로 돌아오자. AI가 쓴 전시 텍스트가 왜 때때로 묘하게 어색한가. 또는 반대로, 왜 어떤 경우에는 전혀 어색하지 않은가. 전자의 경우를 생각해보면, 보통 이런 특징이 있다. 개별 문장은 맞는데 전체가 어딘가 공허하다. 단어 선택이 적절한데 맥락이 어긋난다. 형식은 비평인데 작품에 실제로 닿은 느낌이 없다. 그것은 LLM이 비평 텍스트의 패턴을 학습해서 그럴듯한 비평 형식을 생성했지만, 그 텍스트가 특정 작품의 구체적인 경험에서 나온 것이 아니기 때문이다. 언어-내적 일관성은 있지만, 세계-접지, 즉 실제 작품과의 연결이 약한 것이다.
반대로 AI가 생성한 텍스트가 전혀 어색하지 않은 경우도 있다. 일반적인 정보 전달, 전시 개요 소개, 작가 약력 요약 같은 경우다. 이건 해당 텍스트 유형이 원래부터 비교적 정형화된 패턴을 따르기 때문이다. LLM이 그 패턴을 잘 학습했고, 그 패턴 안에서라면 세계-접지의 부재가 크게 드러나지 않는다. 이 차이를 인식하는 것이 중요하다. AI가 못 하는 것이 있고 잘 하는 것이 있다는 실용적인 이야기가 아니다. 오히려 이 차이를 통해 우리는 ‘이해’가 무엇인지에 대한 더 정교한 질문을 만들 수 있다.
이제 우리 앞에는 두 가지 상이한 방식의 ‘이해’처럼 보이는 것들이 놓여 있다. 상징주의가 추구했던, 명시적 규칙과 논리 구조를 통한 이해. 그리고 LLM이 보여주는, 행동 수행을 통해 드러나는 이해처럼 보이는 능력. 이 둘은 진짜로 다른 것인가. 아니면 같은 것의 다른 표현인가. 다음 회차에서 이 질문을 정면으로 다뤄볼 것이다. 필자가 잠정적으로 도달한 관점, 이해는 단일한 능력이 아니라 두 층위의 결합이라는 제안을 함께 살펴보려고 한다.
허대찬. 미디어문화예술채널 앨리스온 aliceon.co.kr 편집장
1부: 이해의 재배치 01 – AI가 쓴 문장 앞에서 멈칫할 때
2부: 이해의 재배치 02 – 기호주의 AI가 품었던 꿈, 그리고 풀지 못한 질문
3부: 이해의 재배치 03 – 다음 단어를 예측하는 기계가 왜 이해처럼 보이는가