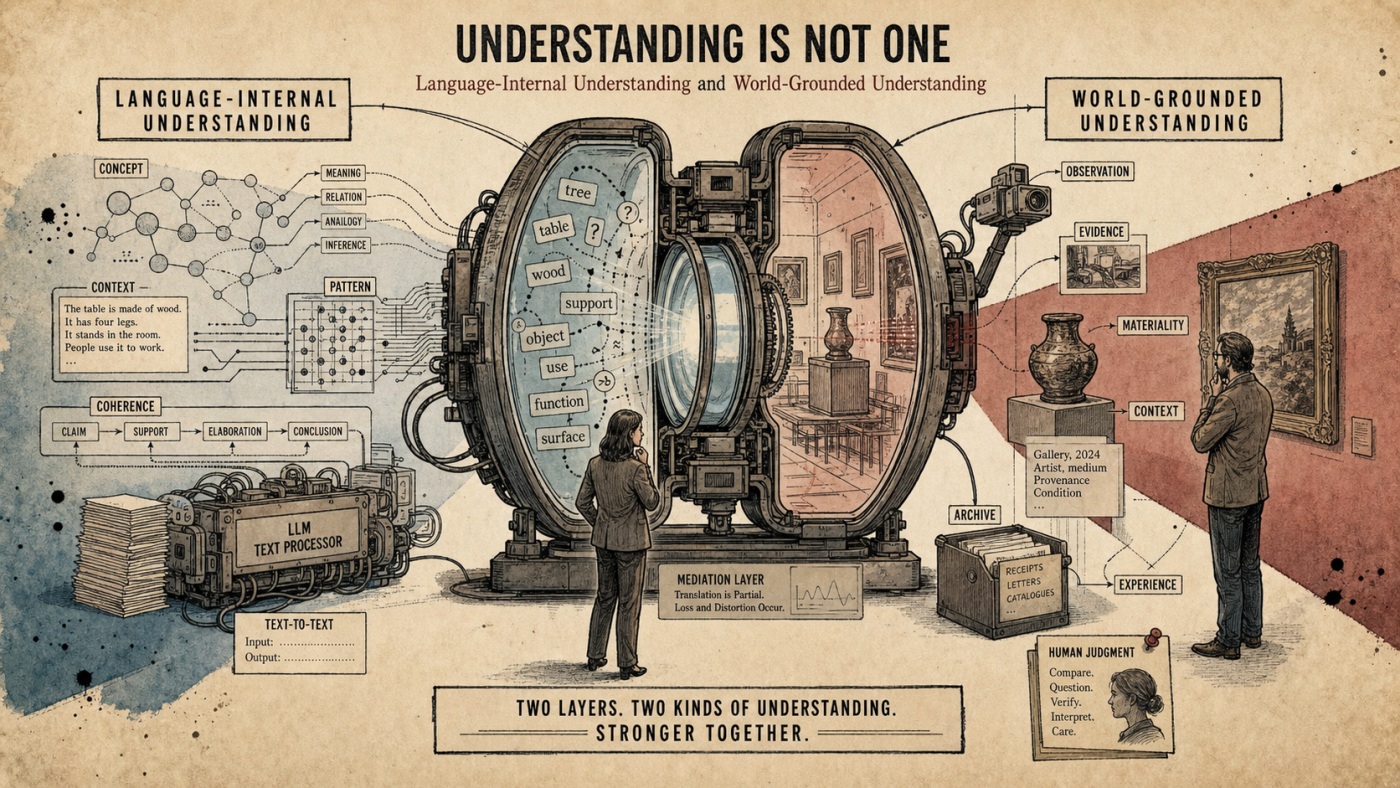
3회차에서 우리는 AI가 생성한 전시 텍스트가 어떤 경우에는 묘하게 공허하고, 어떤 경우에는 꽤 자연스럽게 작동하는 장면을 살펴보았다. 이 차이는 단순히 문장의 완성도나 정보의 정확성만으로 설명되지 않는다. 어떤 텍스트는 말은 맞지만 작품에 닿지 않고, 어떤 텍스트는 비교적 정형화된 정보 전달 안에서 큰 무리 없이 기능한다. 필자는 이 차이를 이해하기 위해, ‘이해’를 하나의 능력으로 보지 않으려 한다. 적어도 LLM 이후의 상황에서 이해는 두 층위로 나뉘어 보인다. 하나는 언어 안에서 개념과 문맥을 정합적으로 연결하는 능력이고, 다른 하나는 그 언어가 실제 세계의 경험, 증거, 물질성, 현장의 저항에 닿는 능력이다.
전자를 ‘언어-내적 이해(language-internal understanding)’, 후자를 ‘세계-접지 이해(world-grounded understanding)’라고 설정해 볼 수 있다. 이 구분은 완성된 이론이라기보다, 지금 우리가 AI와 함께 글을 쓰고, 전시를 설명하고, 작품을 해석할 때 반복해서 마주치는 혼란을 정리하기 위한 작업 가설에 가깝다. 하지만 이 가설은 상당히 실용적이다.“AI가 이해하는가”라는 질문을 “어느 층위의 이해를 말하는가”라는 질문으로 바꾸어주기 때문이다.
우선, ‘언어-내적 이해’는 텍스트의 세계 내부에서 개념들을 정합적으로 연결하는 능력이다. 앞에서 나온 개념이 뒤에서 어떻게 이어지는지 파악하고, 유사한 개념들 사이의 관계를 인식하며, 논리적 모순을 감지하고, 맥락에 맞는 어휘를 선택하는 능력이다. 하나의 글 안에서 문장들이 서로 어긋나지 않고, 논증이 일정한 방향으로 전개되며, 개념들이 그럴듯한 관계망을 이루도록 만드는 힘이라고 할 수 있다.
LLM은 이 층위에서 매우 강력한 수행을 보여준다. 방대한 텍스트를 학습하면서, 어떤 개념이 어떤 맥락에서 등장하는지, 어떤 표현이 어떤 분위기와 연결되는지, 어떤 논증 구조가 설득력 있는 것으로 받아들여지는지를 정교하게 학습했다. 그래서 LLM은 요약, 번역, 문체 변환, 논증 구조 파악, 문단 재구성, 레퍼런스 연결 같은 작업에서 놀라운 능력을 보인다. 이것은 단순한 편의 기능이 아니다. 언어 안에서 의미를 조직하는 능력 자체가 크게 확장된 것이다.
하지만 여기서 바로 다른 질문이 생긴다. 언어 안에서 정합적으로 연결된다고 해서, 그 언어가 실제 세계에 닿아 있다고 말할 수 있을까. 예를 들어 “이 작품은 관객을 압도한다”는 문장을 생각해보자. 이 문장은 미술 비평의 문맥 안에서 아주 자연스럽다. 어떤 작품이 거대한 스케일을 갖고 있고, 강한 시청각적 효과를 만들며, 관객의 신체적 감각에 영향을 준다면 이 표현은 충분히 그럴듯하다. LLM도 이런 문장을 어렵지 않게 만들 수 있다. 비슷한 작품 설명과 전시 리뷰, 미술관 보도자료와 비평문 속에서 이런 표현이 어떻게 사용되는지 이미 학습했기 때문이다.
그러나 그 문장이 정말 작품에 닿아 있는지는 별개의 문제다. 실제로 그 작품 앞에 섰을 때 관객의 몸이 어떻게 반응했는지, 공간의 크기와 동선은 어땠는지, 사운드는 어느 정도였는지, 화면의 밝기와 설치의 밀도는 어떠했는지, 작품이 놓인 제도적 맥락은 무엇이었는지. 이런 것들이 빠진 상태에서 “압도한다”는 말은 비평적 표현처럼 보일 수는 있지만, 작품의 경험에 접지되어 있다고 말하기는 어렵다. 이때 필요한 것이 ‘세계-접지 이해’이다. 이것은 언어가 실제 세계의 검증과 저항에 걸리는 방식이다. 어떤 말이 단지 말들 사이에서 그럴듯하게 이어지는 것이 아니라, 경험, 관찰, 증거, 물질성, 장소, 시간, 관계, 맥락에 의해 지지되거나 반박될 수 있는 상태를 말한다.
“이 약은 효과가 있다”는 문장을 보자. 언어-내적으로는 어려운 문장이 아니다. 주어와 술어가 있고, 주장도 명확하다. 하지만 세계-접지 이해는 다른 질문을 던진다. 어떤 임상 데이터가 있는가. 어떤 조건에서 효과가 있는가. 부작용은 무엇인가. 누구에게는 효과가 있고 누구에게는 없는가. 이 주장은 어떤 방식으로 검증될 수 있는가. 여기서 이해는 문장을 매끄럽게 해석하는 데서 끝나지 않는다. 그 문장이 현실의 어떤 조건과 연결되어 있는지를 확인하는 데까지 나아간다.
비평에서도 마찬가지다. “이 작업은 기술과 인간의 관계를 사유한다”는 문장은, 이제, 너무, 익숙하다. 문제는 이 문장이 맞는가 틀렸는가가 아니다. 오히려 너무 쉽게 맞는 말처럼 보인다는 데 문제가 있다. 어떤 기술인가. 어떤 인간인가. 그 관계는 작품의 어느 구조에서 발생하는가. 관객은 그것을 어떻게 경험하는가. 기술은 단지 소재인가, 아니면 작품의 작동 조건인가. 이 질문들을 통과하지 않은 문장은 언어-내적으로는 안정적일 수 있지만, 세계-접지의 층위에서는 약하다.
좋은 비평은 이 두 층위가 함께 작동할 때 만들어진다. 언어-내적 이해가 없으면 글은 산만해진다. 개념들이 느슨하게 흩어지고, 문장들은 서로 이어지지 않으며, 판단은 감상에 머문다. 반대로 세계-접지 이해가 없으면 글은 공중에 뜬다. 문장은 세련되고 논증은 정연하지만, 정작 작품 앞에서 발생한 사건과는 연결되지 않는다. 형식은 비평인데, 작품을 본 사람의 말처럼 느껴지지 않는 글이 되는 것이다.
이 구분으로 보면, AI가 생성한 전시 텍스트가 왜 어떤 경우에는 유효하고 어떤 경우에는 공허한지도 조금 더 분명해진다. 전시 개요, 작가 약력, 행사 정보, 기본적인 작품 소개처럼 비교적 정형화된 글에서는 언어-내적 이해만으로도 충분히 기능하는 경우가 많다. 이런 글들은 애초에 정해진 형식과 반복되는 표현이 많고, 사실 확인만 적절히 보완된다면 큰 무리 없이 사용할 수 있다.
하지만 특정 작품의 감각적 경험, 현장에서 발생한 긴장, 작가와의 대화에서 나온 미묘한 맥락, 아카이브 자료의 물질적 조건, 전시 공간의 분위기와 관객의 반응을 다루는 순간, 상황은 달라진다. 여기에서는 언어가 세계에 다시 걸려야 한다. 실제로 본 것, 들은 것, 확인한 것, 만난 것, 의심한 것, 판단한 것이 언어 안으로 들어와야 한다. 이 지점에서 LLM의 언어-내적 능력은 강력한 협력자가 될 수 있지만, 그것만으로 비평의 세계-접지를 대신할 수는 없다.
물론 LLM이 세계와 완전히 무관한 것은 아니다. LLM은 세계를 직접 겪지 않지만, 세계에 대해 사람들이 남긴 말들을 엄청난 규모로 학습한다. 전시 리뷰, 논문, 인터뷰, 뉴스, 매뉴얼, SNS의 반응, 기술 문서, 작가 노트 등 세계를 둘러싼 수많은 언어적 흔적들이 학습 데이터 안에 들어 있다. 그러므로 LLM의 언어는 세계와 완전히 단절되어 있지도 않고, 세계에 직접 닿아 있지도 않다. 바로 이 애매한 중간 지대가 우리를 혼란스럽게 만든다.
이제 “AI가 이해하는가”라는 질문은 조금 달라져야 한다. LLM은 언어-내적 이해에 가까운 수행을 강력하게 보여준다. 그러나 세계-접지 이해는 다른 문제다. 그것은 단지 더 많은 텍스트를 학습한다고 자동으로 해결되는 것이 아니라, 관찰, 검증, 경험, 센서, 데이터, 아카이브, 인간의 판단, 현장의 맥락이 어떻게 시스템 안으로 연결되는가의 문제다.
이 지점에서 비평가와 큐레이터의 역할도 다시금 보인다. AI가 글을 매끄럽게 정리하고, 문장의 구조를 만들고, 개념 사이의 연결을 도와줄 수 있다면, 인간의 역할은 단지 더 좋은 문장을 쓰는 데 있지 않다. 오히려 그 문장이 무엇에 닿아야 하는지를 정하는 곳에 있다. 작품 앞에 서는 것, 현장의 공기를 감지하는 것, 작가의 말을 듣는 것, 자료의 출처를 확인하는 것, 보도자료의 언어와 실제 경험 사이의 간극을 살피는 것, 그리고 그 차이를 다시 언어로 붙잡는 것. 이것이 LLM 이후, 비평의 중요한 자리가 될 수 있다.
아카이브의 문제도 마찬가지다. 아카이브는 단지 정보를 잘 정리한 데이터베이스가 아니다. 어떤 자료가 어떤 조건에서 생산되었는지, 무엇이 누락되었는지, 어떤 맥락이 메타데이터로는 포착되지 않는지, 원본의 물질성이나 사건성이 어떻게 남아 있는지를 다루는 실천이다. LLM은 아카이브의 언어를 정리하고 연결하는 데 도움을 줄 수 있지만, 자료가 세계와 맺는 관계 자체를 대신 만들어주지는 않는다. 결국 아카이브에서도 중요한 것은 언어-내적 연결과 세계-접지의 균형이다.
그래서 이 구분은 단순한 이론적 분류가 아니다. AI를 어디에 사용할 수 있고, 어디에서 조심해야 하며, 무엇을 인간이 다시 붙들어야 하는지 판단하기 위한 실천적 기준이 될 수 있다. 요약과 정리, 번역과 구조화, 초안 작성과 표현 조정에서는 LLM의 언어-내적 능력을 적극적으로 활용할 수 있다. 그러나 작품의 의미를 최종적으로 판단하거나, 현장의 경험을 대체하거나, 자료의 신뢰성을 검증하거나, 특정 맥락의 윤리적 무게를 결정하는 일은 다른 층위의 이해를 요구한다.
그러므로 문제는 “AI가 이해하는가, 이해하지 못하는가”가 아니다. 더 정확한 질문은 이것이다. “AI는 어떤 층위에서 이해처럼 작동하는가. 그리고 그 이해가 세계에 닿기 위해서는 무엇이 더 필요한가.” 이렇게 질문을 바꾸면 논쟁의 방향도 조금 달라진다. AI를 과소평가할 필요도 없고, 과대평가할 필요도 없다. LLM이 이미 강력하게 수행하고 있는 언어-내적 능력을 인정하되, 그것이 세계-접지 이해를 자동으로 보장하지 않는다는 점을 함께 보아야 한다. 그리고 바로 그 사이에서 인간의 역할, 비평의 역할, 큐레이션의 역할, 아카이브의 역할이 다시 배치된다.
다음 회차에서는 이 문제를 모델 하나의 능력이 아니라 시스템의 문제로 확장해 볼 것이다. 이해가 두 층위의 결합이라면, “모델이 이해하는가”라는 질문만으로는 충분하지 않다. 오히려 우리는 이렇게 물어야 한다. 어떤 시스템이 어떤 자료와 감각, 검증 절차와 인간의 판단을 연결하면서 이해에 가까운 작동을 만들어내는가. LLM 이후의 이해는 하나의 모델 안에 닫힌 문제가 아니라, 모델과 세계를 어떻게 연결할 것인가의 문제로 이동하고 있다. 그 애매한 사이를 판단하고, 연결하고, 책임지는 일. 어쩌면 그 곳에 LLM 이후 우리가 다시 붙들어 매야 할 인간의 역할이 있다.
허대찬. 미디어문화예술채널 앨리스온 aliceon.co.kr 편집장
1부: 이해의 재배치 01 – AI가 쓴 문장 앞에서 멈칫할 때
2부: 이해의 재배치 02 – 기호주의 AI가 품었던 꿈, 그리고 풀지 못한 질문
3부: 이해의 재배치 03 – 다음 단어를 예측하는 기계가 왜 이해처럼 보이는가
4부: 이해의 재배치 04 – 이해는 하나가 아니다: 언어 안의 이해와 세계에 닿는 이해
참고할 만한 논의
Kyle Mahowald, Anna A. Ivanova, Idan A. Blank, Nancy Kanwisher, Joshua B. Tenenbaum, Evelina Fedorenko, 「Dissociating Language and Thought in Large Language Models: A Cognitive Perspective」, Trends in Cognitive Sciences, 2024.
이 논문은 LLM을 이해하기 위해 “형식적 언어 역량(formal linguistic competence)”과 “기능적 언어 역량(functional linguistic competence)”을 구분한다. 전자는 언어 규칙과 패턴을 다루는 능력이고, 후자는 언어를 실제 세계의 맥락 속에서 사용하는 데 필요한 인지적 능력에 가깝다. 이 글의 ‘언어-내적 이해’와 ‘세계-접지 이해’는 이 구분과 맞닿아 있다. 논문의 규정과 구분에 대해 미디어아트 비평과 큐레이션의 맥락에서 재구성한 것이다. DOI: 10.1016/j.tics.2024.01.011.
Stevan Harnad, 「The Symbol Grounding Problem」, Physica D: Nonlinear Phenomena, 1990.
하르나드의 ‘기호 접지 문제(symbol grounding problem)’는 기호가 다른 기호와의 관계만으로 의미를 가질 수 있는가를 묻는다. 이 글에서 말하는 세계-접지 이해는 그 문제의식을 감각 경험뿐 아니라 관찰, 증거, 아카이브, 현장의 물질성까지 확장한 것이다.
John R. Searle, 「Minds, Brains, and Programs」, Behavioral and Brain Sciences, 1980.
설의 ‘중국어 방’ 사고실험은 규칙에 따라 올바른 출력을 만드는 것과 의미를 이해하는 것이 같은가를 묻는다. 이는 LLM의 유창한 언어 수행이 곧 세계 이해를 보장하는가라는 오늘의 질문과도 이어진다. DOI: 10.1017/S0140525X00005756.
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, Shmargaret Shmitchell, 「On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?」, Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 2021.
벤더 등은 이 논문에서 대규모 언어모델의 유창한 형식 조합이 의미 이해를 보장하지 않는다고 비판한다. 이 논의는 언어-내적 유창함과 세계-접지 이해를 구분해야 한다는 이 글의 문제의식과 연결된다. DOI: 10.1145/3442188.3445922.
Melanie Mitchell, David C. Krakauer, 「The Debate Over Understanding in AI’s Large Language Models」, Proceedings of the National Academy of Sciences, 2023.
미첼과 크라카우어는 LLM이 인간적 의미에서 언어를 이해할 수 있는가를 둘러싼 논쟁을 정리하며, 이해의 여러 양식을 구분하는 확장된 지능 과학이 필요하다고 제안한다. 이 역시 “AI가 이해하는가”라는 단일한 질문을 더 세분화해야 한다는 이 글의 방향과 맞닿아 있다. DOI: 10.1073/pnas.2215907120.
Peter D. Turney, Patrick Pantel, 「From Frequency to Meaning: Vector Space Models of Semantics」, Journal of Artificial Intelligence Research, 2010.
분포 의미론과 벡터 공간 의미론의 흐름을 정리한 대표적인 개관 논문이다. 언어 안에서 단어와 개념의 의미가 함께 등장하는 패턴과 관계망을 통해 계산적으로 포착될 수 있다는 배경을 이해하는 데 도움이 될 수 있다. DOI: 10.1613/jair.2934.
Elia Bruni, Nam Khanh Tran, Marco Baroni, 「Multimodal Distributional Semantics」, Journal of Artificial Intelligence Research, 2014.
논문은 텍스트 기반 분포 의미 표상에 이미지 정보를 결합하는 방식을 제안한다. 이는 텍스트만으로 구성된 의미 표상이 충분한가, 혹은 지각적·시각적 정보와 결합될 필요가 있는가라는 문제를 생각할 때 유용하다. 이 글에서는 세계-접지 이해를 설명하는 보조 논의로 연결할 수 있다. DOI: 10.1613/jair.4135.