4회차에서 우리는 이해를 하나의 능력으로만 보지 않기로 했다. 적어도 LLM 이후의 상황에서 이해는 두 층위로 나뉘어 보인다. 하나는 언어 안에서 개념과 문맥을 정합적으로 연결하는 능력, 즉 언어-내적 이해이다. 다른 하나는 그 언어가 실제 세계의 경험과 증거, 물질성, 현장의 저항에 닿는 능력, 즉 세계-접지 이해이다.
이 구분을 받아들이면 질문은 자연스럽게 다음 자리로 옮겨간다. 이제 문제는 단순히 “AI가 이해하는가”에 머물지 않는다. 우리는 오랫동안 AI를 하나의 독립적인 지능체처럼 상상해왔다. 모델 안에 이해가 있는지 없는지, 모델이 인간을 따라잡았는지 아직 아닌지, 모델이 똑똑한지 그렇지 않은지를 묻는 방식에 익숙하다. 이런 질문은 판단하기 쉽고 논쟁하기도 쉽다. 모델을 하나의 주체처럼 세워두고, 그 안을 들여다보려는 방식이기 때문이다.
하지만 실제로 우리가 마주하는 AI는 그렇게 단순하지 않다. 여기서 말하는 모델은 ChatGPT나 Claude 같은 서비스 전체가 아니라, 그 안에서 언어를 처리하고 응답을 생성하는 핵심 엔진에 가깝다. 우리가 사용하는 서비스는 이 모델 위에 검색, 인터페이스, 안전장치, 파일 처리, 외부 도구, 인간의 검토 절차 등이 결합된 복합적인 시스템이다. 그러니 “모델이 이해하는가”라는 질문은 자칫 우리가 실제로 사용하고 있는 이 복잡한 장치를 모델 하나의 능력으로 환원해버릴 수 있다.
그래서 질문은 다시 바뀌어야 한다. “이 모델은 이해하는가”가 아니라, “어떤 조건에서, 어떤 자료와 절차를 통해, 어떤 시스템이 이해에 가까운 작동을 만들어내는가.” 이해가 모델 내부에 들어 있는 성질만이 아니라, 모델과 자료, 도구, 인간, 검증 절차, 아카이브가 연결되는 방식 속에서 구성된다면, 우리가 봐야 할 것은 모델 하나의 성능이 아니라 그 모델이 놓인 환경과 구조다.
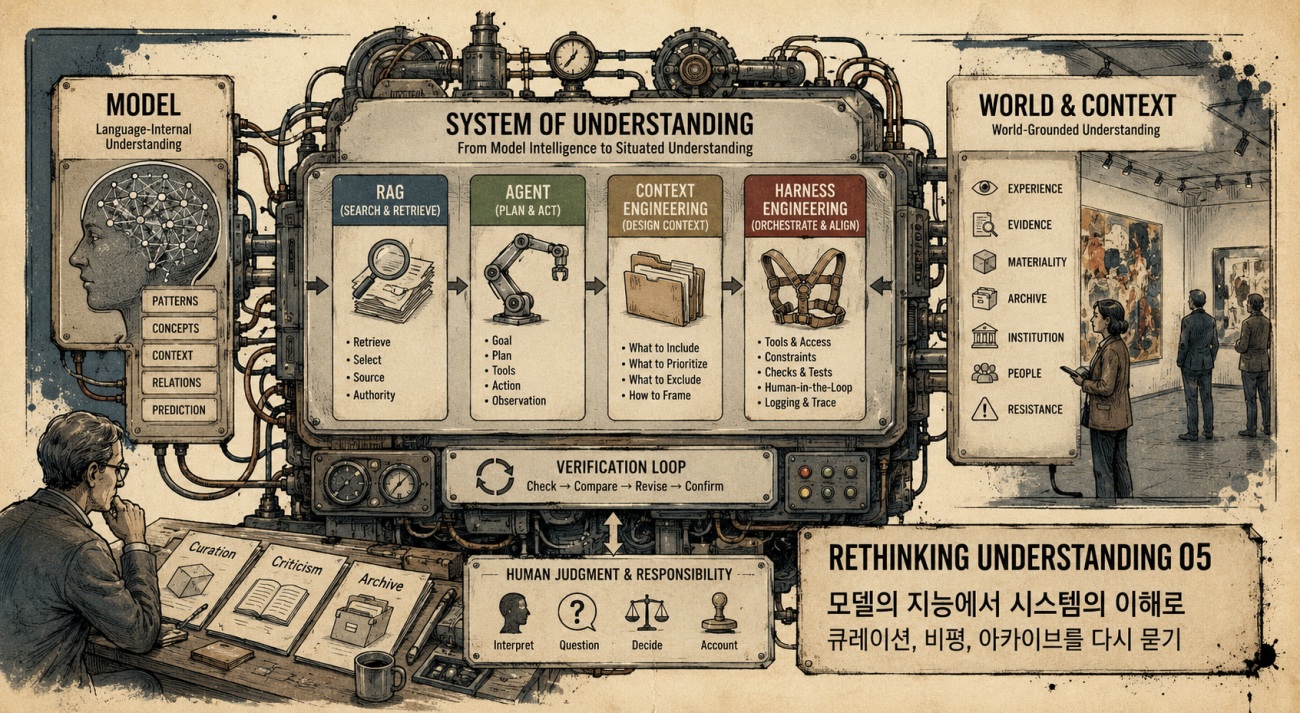
최근 AI 논의에서는 RAG, AI agent, context engineering, harness engineering 같은 말들이 빠르게 확산되고 있다. 처음 들으면 서로 다른 기술 유행어처럼 보인다. 하지만 조금 떨어져서 보면, 이 단어들은 의외로 비슷한 방향을 가리킨다. 이제 중요한 것은 단지 모델 하나의 성능이 아니다. AI를 실제 작업 속에 들여놓는 순간 질문은 달라진다. 이 모델이 얼마나 똑똑한가보다, 무엇을 보고 있는가, 어떤 자료와 연결되는가, 어떤 절차를 거쳐 결과를 만들고 있는가가 더 중요해진다. 다시 말해 최근의 흐름은 단순한 모델 경쟁이 아니다. AI가 어떤 환경 안에서 작동하고, 어떤 자료와 판단 구조를 통해 현실과 연결되는가의 문제로 이동하고 있다.
RAG는 Retrieval-Augmented Generation, 즉 검색 증강 생성이라는 뜻이다. 모델이 답을 생성할 때 외부 문서나 데이터베이스를 검색하고, 그 결과를 함께 참조하도록 만드는 방식이다. 이는 겉으로 보면 단순한 기술적 보완처럼 보인다. 모델이 모르는 정보를 밖에서 찾아 붙이는 장치처럼 보이기 때문이다. 하지만 조금 다르게 보면, RAG는 단순한 검색 기술이 아니라 “무엇을 근거로 삼을 것인가”의 문제와 연결된다. 어떤 문서를 신뢰 가능한 자료로 볼 것인가. 어떤 기록을 검색 대상에 포함할 것인가. 어떤 출처는 왜 제외되는가. 결국 RAG는 기술이면서 동시에 선택과 배열의 구조다. 그렇기에 이 문제는 생각보다 큐레이션과 닮아 있다.
물론 여기서 조심해야 할 지점도 있다. 검색된 문서가 곧 세계는 아니다. RAG가 가져오는 것은 세계 자체가 아니라 세계에 대한 기록, 문서, 데이터, 설명, 흔적이다. 그러므로 RAG를 쓴다고 해서 자동으로 세계-접지 이해가 완성되는 것은 아니다. 어떤 자료를 검색 대상으로 삼았는가. 그 자료는 신뢰할 만한가. 누락된 것은 없는가. 검색 결과가 맥락을 왜곡하지는 않는가. 모델이 그 자료를 과도하게 일반화하지는 않는가. 이 질문들이 함께 따라와야 한다.
이 지점에서 RAG는 기술이면서 동시에 판단의 구조가 된다. 그리고 이 판단의 구조는 미술 현장에도 낯설지 않다. 전시를 기획할 때도 우리는 자료를 가져오고, 배치하고, 해석하고, 때로는 제외한다. 비평을 쓸 때도 어떤 문헌을 읽고 어떤 작가의 말을 신뢰할지 결정한다. 아카이브를 만들 때도 무엇을 기록으로 남기고 무엇을 보조 자료로 둘지 판단한다. 결국 RAG 역시 단순히 정보를 가져오는 기술이 아니다. 어떤 자료를 근거로 삼고, 무엇을 연결하며, 어떤 맥락을 드러낼 것인가를 결정한다는 점에서 이미 하나의 큐레이션 구조에 가깝다.
그런데 최근의 흐름은 여기에서 한 걸음 더 나아간다. 이제 모델은 단순히 검색된 문서를 바탕으로 답을 생성하는 데 그치지 않는다. 목표를 부여받고, 필요한 정보를 찾고, 도구를 호출하고, 중간 결과를 판단하며, 여러 단계를 거쳐 작업을 수행하는 방향으로 이동하고 있다. 이때 등장하는 말이 AI agent다.
에이전트라는 말은 아직 조금 과장되어 들리기도 한다. 마치 AI가 독립적인 행위자가 되어 우리 대신 모든 일을 처리할 것 같은 인상을 주기 때문이다. 하지만 조금 차분히 보면 핵심은 그런 환상이 아니다. 에이전트는 모델이 텍스트를 한 번 생성하고 끝나는 것이 아니라, 도구를 사용하고, 정보를 수집하고, 중간 결과를 확인하고, 다음 행동을 선택하는 방식으로 작동한다는 데 있다. 단순한 텍스트 생성기가 아니라, 정보 수집, 판단, 도구 사용, 실행이 결합된 작동 단위에 가까워지는 것이다.
이 변화는 이번 글의 논지와 직접 연결된다. “모델이 이해하는가”라는 질문은 모델을 고립된 대상으로 본다. 하지만 에이전트의 관점에서 보면 중요한 것은 모델 하나의 내부 상태가 아니다. 모델이 어떤 도구를 사용할 수 있는가, 어떤 자료에 접근할 수 있는가, 어떤 목표를 부여받았는가, 어떤 단계에서 멈추고 확인하는가, 어떤 기준에 따라 행동을 수정하는가가 더 중요해진다. 이해는 점점 더 모델 내부의 속성이 아니라, 모델이 놓인 작동 환경의 문제로 이동한다.
여기서 context engineering이라는 말도 중요해진다. 이 개념은 단순히 “프롬프트를 잘 쓰는 법” 이상의 문제를 가리킨다. 이제 중요한 것은 질문 하나를 잘 만드는 일이 아니다. 모델이 어떤 문서를 함께 읽는가, 어떤 대화 이력을 기억하는가, 어떤 자료를 우선적으로 참고하는가, 어떤 정보는 보지 못하도록 설정하는가를 설계하는 일이 중요해진다.
비평과 큐레이션의 언어로 바꾸면 더 분명해진다. 결국 context engineering은 모델에게 어떤 세계를 보게 할 것인가를 설계하는 일이다. 어떤 작가 노트를 제공할 것인가. 어떤 전시 전경을 참조하게 할 것인가. 어떤 비평문과 인터뷰를 연결할 것인가. 어떤 정보는 제외할 것인가. 어떤 자료는 신뢰할 수 없다고 표시할 것인가. 결국 우리는 AI에게 단지 질문을 던지는 것이 아니라, 하나의 세계를 구성해 보여주고 있는 셈이다.
그리고 harness engineering이라는 말은 이 문제를 실행 환경과 피드백 루프의 차원으로 더 밀고 간다. 이 용어는 아직 넓은 학술 개념이라기보다는 개발자와 코딩 에이전트 담론에서 빠르게 확산 중인 실천 용어에 가깝다. 그래서 이 말을 미술 현장에 그대로 가져오는 것은 조심스럽다. 그럼에도 이 개념은 우리 논의에 꽤 유용한 힌트를 준다.
하네스라는 말은 원래 힘을 가진 존재를 특정한 방향으로 움직이게 하기 위해 장착하는 장치에 가깝다. 말이나 동물에게 채우는 마구를 떠올리면 된다. 힘이 있다고 해서 그것이 곧바로 좋은 방향으로 움직이는 것은 아니다. 힘이 작동할 수 있는 환경, 방향, 제약, 되돌림의 장치가 필요하다.
AI 시스템에서 하네스는 단순한 프롬프트가 아니다. 어떤 도구를 사용할 수 있는지, 어떤 파일에 접근할 수 있는지, 어떤 테스트를 통과해야 하는지, 어떤 기록을 남겨야 하는지, 어디에서 인간의 승인을 받아야 하는지, 오류가 발생했을 때 어떻게 되돌아와야 하는지를 포함한다. 말하자면 에이전트가 제멋대로 움직이지 않도록, 그리고 그 움직임이 검토 가능하고 책임 가능한 형태로 남도록 환경을 설계하는 일이다.
물론 이 개념을 그대로 미술 현장에 적용할 필요는 없지만, 비유적으로는 분명 유용하다. AI를 큐레이션, 비평, 아카이브에 도입한다는 것은 단지 “좋은 프롬프트를 쓰는 법”의 문제가 아니다. AI가 어떤 자료를 보고, 어떤 도구를 쓰고, 어떤 단계에서 멈추며, 누가 검토하고, 어떤 기준으로 수정되는지를 설계하는 문제다. 말하자면 우리는 AI를 사용하는 것만이 아니라, AI가 작동할 수 있는 조건과 울타리, 되돌림의 구조를 함께 설계하고 있는 것이다.
이 흐름을 하나로 묶어보면 이렇게 정리할 수 있다. RAG는 출처와 문서를 연결한다. Agent는 그 연결을 바탕으로 목표를 향해 행동한다. Context engineering은 모델과 에이전트가 무엇을 보게 할지 설계한다. Harness engineering은 그 행동이 신뢰 가능하도록 환경과 피드백 루프를 만든다. 이 모든 흐름은 하나의 방향을 가리킨다. 이해는 더 이상 모델 안에 홀로 들어 있는 것이 아니라, 모델과 자료, 도구, 인간의 판단, 검증 절차가 연결되는 방식 속에서 구성된다.
이제 다시 전시장으로 돌아가보자. 큐레이터가 전시 텍스트를 쓴다고 할 때, 그 일은 단지 문장을 잘 쓰는 일이 아니다. 큐레이터는 작품을 보고, 작가와 대화하고, 이전 작업을 조사하고, 전시장의 조건을 확인하고, 기관의 방향과 관객의 경험을 고려한다. 이 과정은 단순히 정보를 모으는 일이 아니다. 무엇이 이 작품을 말하는 데 필요한 근거인지 판단하는 일이다. 그리고 그렇게 모인 경험과 자료를 하나의 언어로 연결하는 일이다.
AI를 이 과정에 도입한다는 것은, 사실 이 역할 분담을 다시 설계하는 일이다. 어떤 자료를 AI가 참조하게 할 것인가. 어떤 문서는 반드시 인간이 먼저 읽어야 하는가. 어떤 문장은 AI가 초안을 만들 수 있고, 어떤 판단은 인간이 직접 내려야 하는가. 출처는 어떻게 확인할 것인가. 작가의 말과 기관의 보도자료, 관객의 반응과 비평가의 판단은 같은 층위의 자료인가. 이런 질문들이 곧 시스템 설계의 문제다.
여기서 검증 루프라는 개념이 중요해진다. AI가 생성한 내용을 그대로 사용하는 것이 아니라, 외부 기준에 비추어 확인하고, 불일치를 찾고, 수정하고, 다시 판단하는 과정을 시스템 안에 설계하는 것이다. 이 말은 새로워 보이지만, 사실 우리가 이미 잘 알고 있던 일이기도 하다. 좋은 편집자는 원고를 받아 사실을 확인한다. 좋은 연구자는 자신의 주장을 세우고 반례를 찾는다. 좋은 아키비스트는 자료를 기술한 뒤 원본과 대조한다. 좋은 큐레이터는 작가의 진술, 작품의 실제 작동, 전시 공간의 조건, 관객의 경험 사이를 계속 확인한다. 이런 과정은 모두 현실과의 연결을 유지하기 위한 절차다.
AI 시스템에서도 마찬가지다. 모델이 생성한 텍스트를 신뢰할 수 있는 출처와 대조하고, 출처가 불분명한 문장을 표시하고, 사실과 해석을 구분하고, 인간이 최종 판단하는 절차가 필요하다. 같은 모델을 사용하더라도 이 루프가 설계되어 있느냐 없느냐에 따라 결과물의 성격은 완전히 달라진다. 검증 루프 없는 AI 텍스트는 매끄러울 수는 있지만, 책임질 수 있는 텍스트가 되기는 어렵다.
이제 중요한 질문은 “모델이 얼마나 똑똑한가”가 아니다. “이 시스템은 세계와의 연결을 어떻게 설계하고 있는가”이다. 어떤 자료를 가져오는가. 어떤 방식으로 확인하는가. 어떤 단계에서 인간의 판단이 개입하는가. 오류를 발견했을 때 어떻게 수정하는가. 출처와 책임은 어디에 남는가. 이 질문들이야말로 AI 시대의 큐레이션과 비평, 아카이브가 다시 붙들어야 할 질문이다.
한편 LLM이 가져온 또 다른 변화도 놓치면 안 된다. 언어-내적 이해의 압도적 확장이다. LLM은 텍스트를 연결하는 능력에서 놀라운 힘을 보여준다. 하나의 개념을 다른 개념과 연결하고, 낯선 문헌을 요약하고, 서로 다른 글의 구조를 비교하고, 문체를 변환하고, 참고할 만한 맥락을 제안한다. 말하자면 LLM은 인터텍스추얼리티의 엔진처럼 작동한다.
이것은 연구자와 비평가에게 분명 강력한 도구다. 나 역시 이 연재를 쓰는 과정에서 AI의 언어-내적 연결 능력을 적극적으로 활용했다. 생각의 흐름을 정리하고, 개념 사이의 관계를 점검하고, 참고할 논의를 찾고, 문장의 리듬을 다듬는 과정에서 AI는 실제 협력자로 기능했다. 그러므로 AI의 능력을 단순히 과소평가할 필요는 없다.
문제는 이 능력이 너무 쉽게 작동한다는 데 있다. 텍스트가 너무 빨리 만들어진다. 레퍼런스가 너무 자연스럽게 연결된다. 문장은 매끄럽고, 구조는 안정적이며, 개념은 그럴듯하게 배열된다. 그런데 이 모든 것이 세계와의 실제 마찰 없이 이루어질 때, 결과물은 풍부해 보이지만 어딘가 비어 있는 텍스트가 된다.
미술 현장에서도 이미 이런 장면을 자주 본다. AI가 작성한 작가 노트, AI가 다듬은 전시 소개문, AI가 구성한 기획서, AI가 생성한 비평 초안. 문장만 보면 크게 틀린 곳이 없다. 그런데 읽다 보면 이상하게 작품 앞에 선 사람의 말처럼 느껴지지 않는다. 작품의 표면을 본 흔적, 공간에서 머뭇거린 시간, 작가와의 대화에서 생긴 어긋남, 설치 과정에서 발생한 물질적 조건, 관객의 반응에서 확인한 긴장감이 빠져 있다.
이 공허함을 단순히 “AI가 글을 못 쓴다”로 치부하면 핵심을 놓치게 된다. 오히려 이 어색함은 중요한 신호에 가깝다. 언어 안에서는 충분히 매끄럽지만, 실제 경험과 부딪힌 흔적은 사라져 있는 상태. 개념은 안정적으로 연결되어 있지만, 특정 시간과 장소에 묶인 감각은 빠져 있는 상태. 작품을 설명하는 것처럼 보이지만, 정작 작품 앞에서 머뭇거린 몸의 흔적은 남아 있지 않은 상태.
이 감각은 결국 우리에게 하나의 사실을 다시 보여준다. 언어적 정합성만으로는 비평이 완성되지 않는다는 것. 비평은 여전히 경험과 관찰, 확인과 판단의 층위를 필요로 한다는 것이다. 이 맥락에서 큐레이션과 비평의 역할은 사라지는 것이 아니라 재배치된다. AI가 언어-내적 수행을 강력하게 담당할 수 있다면, 큐레이터와 비평가의 고유한 기여는 어디에 있는가. 나는 그것이 적어도 두 가지 방향에서 다시 중요해진다고 본다.
이 맥락에서 큐레이션과 비평의 역할은 사라지는 것이 아니라 재배치된다. AI가 언어-내적 수행을 강력하게 담당할 수 있다면, 큐레이터와 비평가는 더 이상 모든 문장을 혼자 생산하는 사람으로만 남지 않는다. 오히려 그들은 언어가 다시 현실에 닿을 수 있도록 재료를 가져오는 사람에 가까워진다. 작품 앞에 서는 것, 현장을 경험하는 것, 설치 과정을 지켜보는 것, 작가와 대화하는 것, 아카이브를 직접 확인하는 것, 자료의 출처를 점검하는 것. 이 경험과 판단이 현실과 연결된 비평의 재료가 된다.
동시에 큐레이터와 비평가는 시스템을 설계하는 사람으로도 이동한다. AI를 어디에 사용할 것인가. 어떤 자료를 연결할 것인가. 어떤 검증 루프를 둘 것인가. 어떤 단계에서 인간이 개입해야 하는가. 무엇을 자동화하고, 무엇을 자동화하지 않을 것인가. 이 판단은 앞으로 비평과 큐레이션의 부차적 기술이 아니라, 글과 전시의 신뢰도를 결정하는 핵심 조건이 될 것이다.
이 역할은 사실 완전히 새로운 것이 아니다. 좋은 큐레이터와 비평가는 언제나 현장 경험을 가져오고, 자료를 선별하고, 판단의 근거를 만들고, 그것을 언어로 연결해왔다. 달라지는 것은 언어-내적 작업의 상당 부분을 이제 AI와 나눌 수 있게 되었다는 점이다. 그리고 이 분담이 명확할수록 인간의 역할은 더 흐려지는 것이 아니라 오히려 선명해진다.
마지막으로 아카이브에 대해 이야기해야 한다. AI가 생성한 텍스트가 많아질수록, 아카이브의 가치는 오히려 더 커진다. 왜냐하면 아카이브는 말을 특정 시점의 현실에 다시 묶어두는 장치이기 때문이다. 누가 언제 무엇을 보았는가. 어떤 조건에서 기록이 생산되었는가. 어떤 장비와 공간, 어떤 사회적 상황 속에서 작품이 작동했는가.
물론 아카이브 역시 완전할 수는 없다. 모든 기록은 선택과 누락을 포함한다. 하지만 바로 그렇기 때문에 아카이브는 더 중요해진다. 무엇이 기록되었는지뿐 아니라, 무엇이 빠졌고 왜 빠졌는지까지 함께 드러내야 하기 때문이다.
생성형 AI 시대에는 특히 그렇다. AI는 점점 더 그럴듯한 설명을 빠르게 만들어낸다. 그러나 그럴듯함이 강해질수록, 오히려 특정 시간과 장소에 닿아 있는 기록의 가치는 더 커진다. 현장에서 촬영된 사진, 설치 당시의 기술 문서, 작가와의 대화 기록, 실제 관객 반응, 수정 이력과 메타데이터 같은 것들은 단순한 부가 정보가 아니다. 그것들은 해석이 다시 현실에 닿을 수 있도록 붙들어주는 증거의 구조다.
미디어아트 아카이빙에서 이 문제는 더욱 중요하다. 퍼포먼스, 인터랙티브 설치, 시간 기반 작업, 네트워크 기반 작업은 작품의 의미가 고정된 오브제 안에만 머물지 않는다. 작품은 작동하고, 실패하고, 반응하고, 갱신되고, 사라진다. 관객의 경험, 장비의 조건, 소프트웨어 버전, 공간의 배치, 실행 당시의 사회적 맥락이 작품의 일부가 된다. 그러므로 미디어아트 아카이브는 단순히 이미지를 모으는 일이 아니라, 작품이 세계와 접촉했던 조건을 기록하는 일이다.
이 관점에서 보면 AI 시대의 아카이브는 단지 과거를 보존하는 장치가 아니다. 그것은 미래의 해석이 다시 현실과 연결될 수 있도록 만드는 기반이다. AI가 아무리 그럴듯한 작품 설명을 생성해도, 특정 시점의 현장과 자료에 닿아 있는 기록을 대신할 수는 없다. 오히려 AI가 강력해질수록, 우리는 더 신뢰할 수 있는 아카이브, 더 세심한 메타데이터, 더 분명한 출처, 더 풍부한 현장 기록을 필요로 하게 된다.
이제 우리는 1회차의 질문으로 다시 돌아올 수 있다. AI가 쓴 전시 텍스트 앞에서 우리가 느꼈던 그 묘한 멈칫거림. 그것은 단지 “이 문장을 누가 썼는가”의 문제가 아니었다. 더 중요한 것은 그 문장이 무엇에 닿아 있는가였다. 작품을 본 경험에 닿아 있는가. 현장의 공기에 닿아 있는가. 작가와의 대화, 설치 과정의 시행착오, 실제 관객의 반응, 확인 가능한 자료와 출처에 닿아 있는가. 아니면 그저 문장과 문장 사이를 매끄럽게 이동하고 있는가. 그러므로 LLM 이후의 이해는 모델 내부에 닫힌 문제가 아니다. 이해는 모델과 문서, 아카이브와 현장, 인간의 판단과 검증 절차가 어떻게 연결되는가의 문제로 이동하고 있다.
그리고 바로 이 지점에서 큐레이션과 비평의 역할도 다시 보이기 시작한다. 앞으로 중요한 것은 단지 더 좋은 문장을 생산하는 일이 아니다. 무엇을 근거로 삼을 것인가. 무엇을 확인할 것인가. 어떤 판단을 자동화하지 않을 것인가. 어떤 연결에 책임질 것인가. 어쩌면 LLM 이후 인간의 역할은 단순히 언어를 생산하는 사람이 아니라, 언어가 다시 세계에 걸리도록 만드는 사람에 가까워지고 있는지도 모른다.
다음 회차에서는 이 연재를 마무리하며 질문을 조금 더 넓혀보려 한다. 우리가 갱신해야 할 것은 단지 AI에 대한 평가만이 아닐지도 모른다. 어쩌면 지금 다시 묻고 있는 것은 이해 자체에 대한 우리의 계약인지도 모른다. 우리는 무엇을 이해라고 부를 것인가. 어떤 조건에서 이해했다고 인정할 것인가. 그리고 그 인정의 책임을 누구에게, 어떤 절차 속에 남겨둘 것인가.
허대찬. 미디어문화예술채널 앨리스온 aliceon.co.kr 편집장
1부: 이해의 재배치 01 – AI가 쓴 문장 앞에서 멈칫할 때
2부: 이해의 재배치 02 – 기호주의 AI가 품었던 꿈, 그리고 풀지 못한 질문
3부: 이해의 재배치 03 – 다음 단어를 예측하는 기계가 왜 이해처럼 보이는가
4부: 이해의 재배치 04 – 이해는 하나가 아니다: 언어 안의 이해와 세계에 닿는 이해
참고할 만한 논의
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela, 「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks」, NeurIPS, 2020. 링크: https://arxiv.org/abs/2005.11401 RAG라는 용어와 구조를 널리 알린 대표 논문이다. 사전학습 모델의 매개변수적 기억과 외부 문서 인덱스라는 비매개변수적 기억을 결합해 지식 집약적 과제에서 생성 성능을 높이는 방식을 제안한다.
IBM, 「What is RAG?」. 링크: https://www.ibm.com/think/topics/retrieval-augmented-generation RAG를 외부 지식 기반과 AI 모델을 연결해 응답의 관련성과 품질을 높이는 아키텍처로 설명한다. 기술적 설명이 비교적 명료해 웹 독자가 참고하기 쉽다.
OpenAI, 「Agents」, OpenAI Cookbook. 링크: https://developers.openai.com/cookbook/topic/agents 에이전트를 사용자를 대신해 독립적으로 작업을 수행하는 시스템으로 설명한다. 에이전트는 LLM을 사용해 지시를 실행하고 결정을 내리며, 도구를 통해 맥락을 수집하고 행동한다.
Anthropic, 「Effective Context Engineering for AI Agents」, 2025. 링크: https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents 컨텍스트 엔지니어링을 LLM 추론 과정에서 모델에게 제공되는 정보의 집합을 선별하고 유지하는 전략으로 설명한다. 프롬프트 작성에서 시스템 설계로 논의가 이동하고 있음을 보여주는 자료다.
OpenAI, Ryan Lopopolo, 「Harness Engineering: Leveraging Codex in an Agent-First World」, 2026. 링크: https://openai.com/index/harness-engineering/ 하네스 엔지니어링을 에이전트가 신뢰 가능하게 작업할 수 있도록 환경, 테스트, 문서, 배포, 관측 가능성 등을 설계하는 실천으로 다룬다. 아직 넓은 학술 용어라기보다는 코딩 에이전트 담론에서 부상 중인 실천 개념으로 보는 것이 적절하다.
NIST, 「Artificial Intelligence Risk Management Framework 1.0」, 2023. 링크: https://nvlpubs.nist.gov/nistpubs/ai/nist.ai.100-1.pdf AI 시스템의 신뢰성과 위험 관리를 위해 테스트, 평가, 검증, 확인 절차의 중요성을 강조한다. 이 글에서는 검증 루프를 시스템 수준의 현실 연결 절차로 이해하는 데 참고할 수 있다.